One of the building blocks of the open metaverse Linden Lab is going to build via the open Second Life Grid Architecture Working Group are the so-called „Capabilities“. These are even in use already in the existing Second Life Grid but will be used even more in the future. In fact most of web services we are going to build will be encapsuled in Capabilities.
But what are Capabilities actually? To understand this we should look at how ReST based Web Services look today.
Authentication in RESTful Web Services
Usually if you want to authenticate with some website you do this via a login and this website then sets a cookie in your browser. So authentication is mainly done via a header inside the HTTP request (because the Cookie is sent in the header). If we look at the Amazon Web Services , e.g. how to create a new bucket for Amazon S3 we see a similar mechanism:
PUT / HTTP/1.1 Host: colorpictures.s3.amazonaws.com Content-Length: 0 Date: Wed, 01 Mar 2006 12:00:00 GMT Authorization: AWS 15B4D3461F177624206A:xQE0diMbLRepdf3YB+FIEXAMPLE=
So in this case the authorization key is sent as header field as well.
How do Capabilities work?
Capabilities are used for authorization, too. In fact they are used instead of those header fields. A capability here is simply a URL which represent the web service. It might look like this:
https://capsserrver.mydomain.com/caps/b658bd6e-ae29-11dc-83f0-0017f2c69b9c
This URL is only known to you and it allows you to call a certain web service which is hidden behind that URL. As there is a random string (a UUID in this case) is involved it is not guessable and thus can act as authorization. It also means that you do not call the web service in question directly but always via such a capability URL.
The web service behind that cap might actually resolve to something like this:
http://assetserver.local/users/tao_takashi/inventory/chair
The host assetserver.local will never be exposed to the internet in this scenario, only the caps. The caps server then takes this random string and looks up the original URL and proxies the request to that web service (the assetserver one in this case). As you can also see, your username (tao_takashi) is not transferred aswell.
How does the process run in detail?
So let me explain from the start: First you login by accessing a publically available web service on the login server. You send it your username and password and among other things you will get a seed capability back. The diagram below shows the sequence:
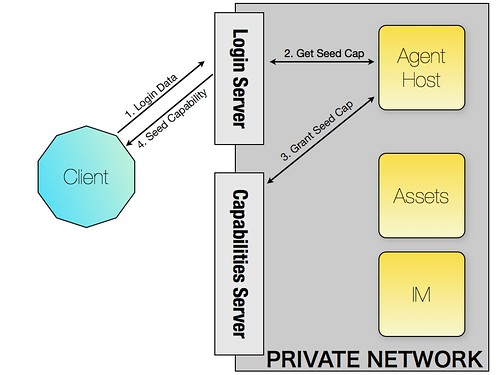
- You POST your login data to the login server
- The login server starts a new session on an agent host. This know you are logged in, who you are and so on.
- The agent host now has a web service which could be
http://agenthost.local/tao_takashi/seedand it wants to grant the client a capability for that. It does that by asking the Capability Server for a capability URL for the mentioned URL (in fact tao_takashi could also be an internal session id which eventually makes more sense to be able to attach this functionality to a session). - The Agent host sends the new capability URL via the login server as a response to the POST in step 1 back to the client. This seed capability might look like
http://caps.domain.com/caps/18761762(usually they are UUIDs as they are more random but shorter makes more sense here for the diagram).
Now of course you cannot do much more as you only know the seed capability URL. But this one in fact is used to ask for further capabilities as the seed capability is indirectly bound to your user session. Thus it’s all the client needs to send to the server should it need more services. Especially there is no need to send any header information containing authorization information.
Now let’s imagine we want to access an inventory item. We first need to ask the seed capability to grant us the right to access an item called „chair“ (this is simplified, of course you first need to know there is an item called „chair“ and it’s probably more likely an UUID than a name etc.). To do this we simply send a request for this new capability to the seed capability. The seed capability is received by the caps server which looks up the internal URL for that caps URL and proxies the request on (in our case to http://agenthost.local/tao_takashi/seed).
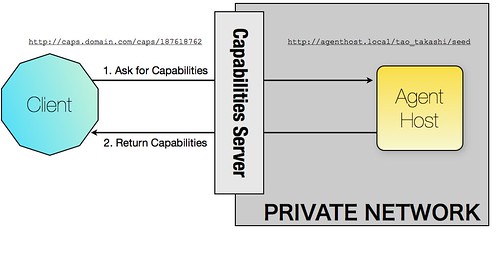
The seed cap implementation now checks if the user is allowed to use that web service. If so it does the same process as for the seed capability which means it asks the caps server to create a new capability URL for the internal URL. This might look like http://caps.comain.com/caps/99988171 for the internal URL http://assets.local/tao_takashi/chair.
In the next diagram we can see how this web service is called then:
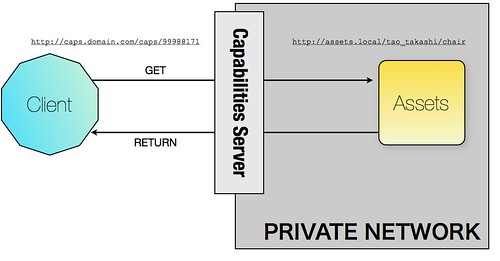
Once again the caps server only acts as a proxy.
Please do also note that those capabilities might expire after some time. Also note that Linden Lab does not want caps with paths in them as it adds complexity in handling that path. One example might be to grant a caps just for retrieving inventory and add the actual inventory path to that (if we decide to map the folder structure of your inventory directly to a URL). Then it’s the question what happens if there is a „..“ in that path. There seem to be some concerns that this might lead to problems regarding security. Thus Linden Lab’s proposal is to grant a cap for each individual inventory item.
What are the benefits of using Capabilities vs. headers
To see the advantage we need to have a look at how things work at Linden Lab. They have a lot of components written in various languages and frameworks which would need to authenticate the user and hold session information (or access it). This means that you’d have to implement security mechanism in each of these modules. And test it of course.
Having capabilities removes that burden. Security is done in a central place, the seed capability and all those modules don’t need to even care about it. They might simply be called like http://imagehost.local/upload_image?user=TaoTakashi&data=…. from the caps server. They don’t need to check anymore if this user is really allowed to upload as this has been done before.
The question is of course how the seed cap knows what service to grant to which user. But for now this seems to be quite easy as there are not too many levels of authorization, mainly „is god because works for Linden Lab“ or „normal resident“ and thus might be denied some of the capabilities such as shutting down the grid.
If you also think about the idea that the new Second Life Grid Architecture is all about interoperability you might also want to mix parts implemented by different people inside your installation. Like the asset server could come from person X, the IM server from party Y and so on. All these parts would need to handle authorization themselves and somehow connect to the session host which knows about permissions. Or to some database. So in this case capabilities are probably easier for plugging a system together.
Of course the seed capability has to know about all the modules and how to access them with the right URL syntax. But this should be defined in the protocol anyway.
The capability server itself is also a quite simple application as it only needs to hold a mapping of internal vs. external URLs and basically two methods, one for granting a new cap and one for accessing one (which is the proxy part). Linden Lab even considers to open source this module.
What might be the drawbacks of using capabilities?
One drawback is of course the increased network traffic. For each web service you want to use you first need to ask the seed capability for permission and the caps URL. Only then can you call the web service. This means that in the end you will have 2 HTTP requests between client and server. Of course these caps URLs can be cached on the client side so you don’t need to request them again if you want to use the same web service twice. It needs to be seen how much of a problem this will be.
Then it adds complexity. People are not used to that concept and as I know from my Plone and Zope work it’s hard to get people on board if there are too many new concepts. This might be also the case for the Second Life Grid Working Group.
Another point is that the seed capability basically needs to know all the other modules and how to call them. This is maybe not such a big problem as some part needs to know about this anyway. Either the client in a header based auth scenario or the seed cap in this case. Actually maybe it’s even a benefit as you don’t need to change the client should you want to change the call definition.
Conclusion
Well, I am not yet sure how useful capabilities are and if they don’t bring us some performance constraints if they are more widely used. Of course they make sense if we look at the heterogenous part scenario above. But even here we could say that not the client asks the seed cap for permission but the module on the local network does. The client might still call something like http://assets.local/tao_takashi/chair but the web service implementation could then ask a central service on the local network for permission to use it (here of course the session id or auth key would be needed inside the header). This at least would be better for performance as these components are closer together network-wise.
I still have to think about it and some discussion would be great here. Then again Linden Lab probably wants to keep them the way they designed them for now as their priority in this project is to move the existing infrastructure to the new one at some part and they probably wouldn’t want to change too much if not really needed.
Tags: slga, awg, lindenlab, secondlife, grid, capabilities, technical